|
The Forrester Wave™: Supplier Value Management Platforms, Q3 2024 See Report
Blog »
Invoice Data Capture with AI: Rule-based versus cognitive field extraction
by Doug Keeley

In this article, we share some of our research and development efforts from our AI team at Ivalua.
The R&D team at Ivalua has been conducting various research efforts around AI. One to highlight includes, the analysis of documents with greater accuracy, by taking advantage of the new deep learning based methods and experimenting on new AI infrastructures. The first objective was to extract fields from structured documents, namely invoices.
As we humans know and expect most of the time, invoice documents have characteristics that other documents do not share. In most cases, the numeric information (numbers, prices, totals, quantities, …) are aligned in different varieties, that might be drawn with explicit lines or separators, or something has to be guessed by the alignment of the characters. This kind of inference makes the use of non-AI algorithms far from our common understanding of an invoice. Another characteristic of invoices is that some fields are required, such as the client, the supplier, the invoice number, the total amount… and they have a common position in the document: the layout possibility is limited and helps humans to easily understand invoices.
The purpose of Artificial Intelligence is to recreate the intuition of human intelligence when reading an invoice. This is different based on if global or local, and is being driven by the number of previously read invoices. For that purpose, we believe that deep learning methods will become particularly useful and common in this area.
The methods used can be the image of the document itself directly, or the characters extracted by an OCR algorithm. In one case, it is a computer vision problem, in the other case, a natural language processing problem. Both problems benefit today from deep learning advances when achieving state-of-the-art accuracy.
At first, we experimented with computer vision. However, document image analysis suffers from the lack of research in the domain: most state-of-the-art computer vision deep learning networks and architectures have been developed for use with natural images. In order to achieve a better analysis, we started with the first neural networks invented by LeCun on the digits dataset, where the problem was to identify the digit number. We extended the number of classes to cover all characters in the alphabet (not only the digits) and adopted the classical object detection frameworks to train the model to “ocrize” the document. It was quite easy to get some training data to train the networks in their framework since any OCR can be used to create the data from any document. Here is the result we got:

These results gave us the first root network layers to build our complete document invoice neural networks. Here again, multiple frameworks are possible to understand an invoice and we choose the segmentation frameworks for which each pixel of the invoice document has to be classified into one class or label. Such a segmentation of the document is very useful to help us extract field values from the invoice with more confidence.
The classes to segment correspond to commonly found data in an invoice:
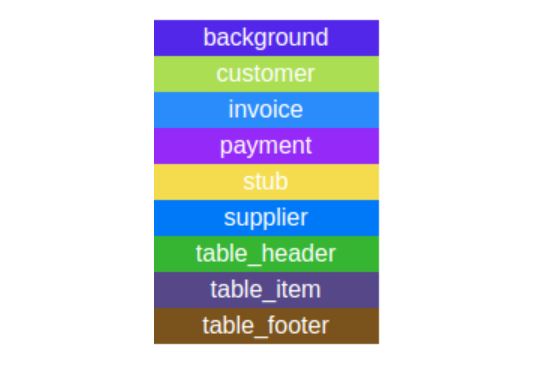
The creation of the dataset required the help of extra resources to annotate our invoice documents with the right classes. We also had to define annotation rules and definitions. For example, we considered the area where the total information is as the table footer, and this footer can be detached from the item table in many cases. We put all the invoice data such as invoice number, date, due date, … that does not correspond to a customer, a supplier, or a table, under the label ‘invoice’.
After all this was set, we trained our models and got the following results on validation data:

What is shown here is the segmentation map predicted by the system. It shows where the different classes of information are the most probably located. For example you can clearly see the customer information in light green on upper right and the table footer class detected on the bottom right of the invoice, in brown.
Experiments show that traditional deep learning networks for computer vision are not that efficient on images of invoices, however the networks we developed at Ivalua perform better by a significant margin.
Our research and development works will be brought back together into the product development roadmap to build new functionality and more reliable features on invoice documents in the next releases. As a result, customers can expect better automatic invoice reading, automatic supplier data update and error control.

Vishal Patel
VP Product Marketing
Vishal has spent the last 15 years in various roles within the Procurement and Supply Chain technology market. As an industry analyst, he researched and advised organizations in various industries on best and innovative practices, digitization and optimization. He brings a thorough understanding of market trends and digital technologies that can help enterprises be more effective with their Procurement and Supply Chain strategies. He works to ensure that organizations are empowered with technology platforms that enable flexibility, innovation, and agility.
You can connect with Vishal on Linkedin
You May Also Like
-

Report Recap | Purpose-driven Procurement: Entering the Age of Holistic Value
-

3 Powerful Ways Procurement will Drive the 2030 Saudi Vision Transformation
-

Inflation + Source-to-Pay Strategies: The Cure for the Common Price Hike